

I’m super excited to share the release (into Preview) of vector indexing support for CockroachDB. It’s exciting for a few reasons, but for me the most exciting piece is how it represents the innovative engineering design that exemplifies the best that Cockroach Labs has to offer.
We’ve had to solve for vector indexing without compromising resilience, scalability, or transactional consistency. And we had to do it while keeping up with the features that make us so popular, including geo-partitioning and operational simplicity.
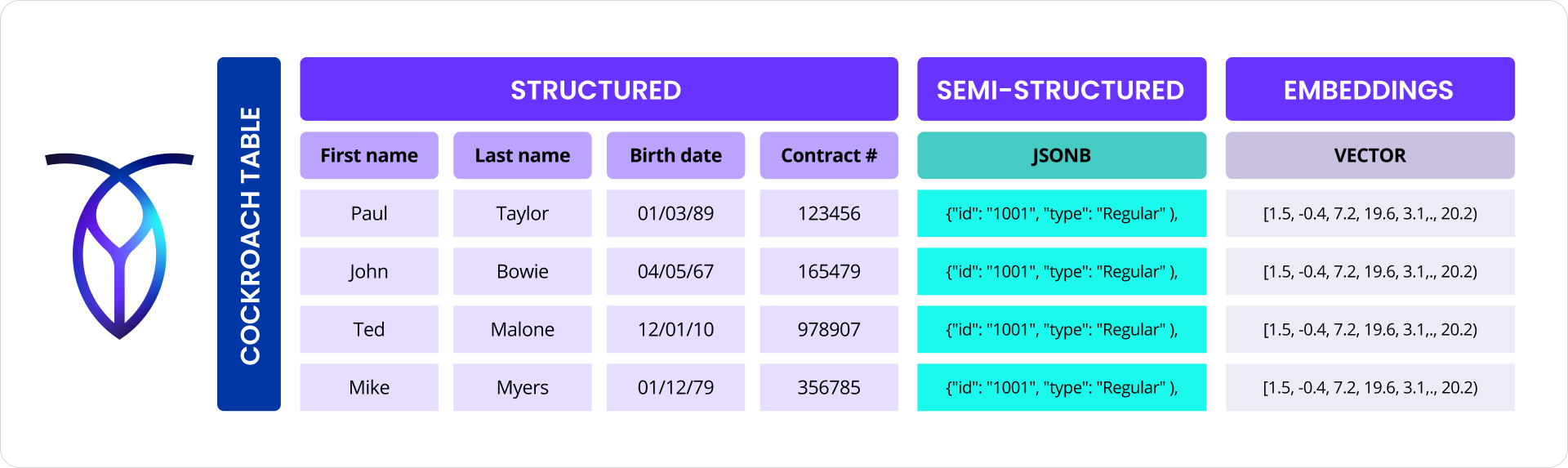
With the 25.2 release we deliver vector indexing to further enable customers to combine transactional data with vector data into a single data store, all without compromising the underlying fundamental promises of distributed SQL.
Background: pgvector support
CockroachDB 24.2 introduced support for multi-dimensional vectors with syntax, data types, and functions that are compatible with the now standard pgvector PostgreSQL extension. Vectors with hundreds or even thousands of dimensions could be created, updated, and searched with that release last fall.
In contrast to traditional search methods that rely on exact matches, vector search uses the concept of similarity to deliver more relevant and nuanced results. Similarity search is becoming increasingly important for applications such as image search, document retrieval, recommendation systems, natural language processing, and LLM integrations.
In the context of text search, vectors can capture the semantic meaning of words, phrases, or entire documents. For example, with vector search, a user can search for “the Avengers” and can also get recommendations for “Marvel superheroes” and “the Fantastic Four.” Text, images, audio, and other representations are embedded into vectors such that similar vectors imply that the original representations are also similar. Deep learning neural networks are now used by companies like OpenAI to create these vector embeddings, sometimes with thousands of dimensions. Embedding reduces hard, seemingly distinct problems like image recognition and semantic text search into the easier, generalized problem of finding vectors that are nearby one another in high-dimensional space.
Until now, our implementation has been limited in an important way. Only brute-force searching in O(N) time was supported. Users could not create a secondary index to accelerate searches. Therefore, as the number of vectors grew to the millions, searches became prohibitively slow, reducing the utility of our vector support.
With version 25.2 we’ve remedied this limitation, and are introducing a new vector indexing innovation — Cockroach-SPANN (C-SPANN for short).
C-SPANN: A new distributed vector indexing algorithm
C-SPANN adapts Microsoft’s SPANN and SPFresh algorithms to work well with CockroachDB’s unique distributed architecture. C-SPANN enables CockroachDB to efficiently answer approximate nearest neighbor (ANN) queries with high accuracy, low latency, and fresh results — all at the scale and throughput that our customers demand, even with billions of indexed vectors.
C-SPANN is currently in public preview, and has not achieved all of the following (yet)...however, I want to share the goals behind C-SPANN so you know where CockroachDB is headed:
Accuracy. Vector search accuracy is typically measured in terms of “recall@k”, which is the percentage of the k most similar vectors returned by the search. For example, if a search results in 80% recall@10, then it returns 8 of the 10 vectors that are most similar to the query vector. The remaining 2 vectors are not among the top 10 best matches (though they still may be very good matches).
State-of-the-art vector indexing algorithms can generally achieve 99%+ recall for real-world datasets with ~1M vectors, though that level of accuracy comes with a high cost. If a particular search can tolerate lower accuracy, then results can be returned with substantially less resource usage and sometimes with less latency. Because of this trade-off, search accuracy is tunable by the user on a per-query basis. In addition, we have chosen an algorithm that can achieve 99% recall rates with reasonable resource usage, as customers will expect this kind of performance.
Freshness. This was one of the tricky problems we had to solve. Almost all the vector indexing literature ignores the problem of freshness, whereby an index can be updated incrementally as new vectors are inserted and existing vectors are deleted. Instead, most papers assume that all vectors to be indexed are available up-front and that the index can be built in a near-optimal way from those vectors. Updates to the index after that point are often difficult to implement, resource-intensive, slow, require central coordination, and/or cause degradation to index quality. None of which is acceptable for our implementation.
Users expect a relational OLTP database like CockroachDB to serve fresh results, immediately including newly inserted vectors and immediately removing deleted vectors from search results. Therefore, we created an algorithm that supports fresh results without serious downsides such as high resource consumption, sluggish updates, or significant index quality degradation. This last point is important, since index degradation might require periodic index rebuilds, which can be time-consuming and expensive. Furthermore, the freshness algorithm does not rely on central coordination, such as a single SQL node to which all queries must be routed. This last point is important to understand because we had to keep the integrity of the underlying distributed SQL core promises to our customers while also delivering index freshness.
Scalability. Most research focuses on in-memory vector indexes that can handle millions of vectors, with the goal of achieving single-digit latency and hundreds of QPS per vCPU. However, several excellent papers over the last few years extend the research into disk-based indexes that can efficiently query billions of vectors.
Given that one of CockroachDB’s main differentiators is our ability to scale, we have chosen a disk-friendly algorithm that can reach arbitrary levels of scale, both in terms of storage and QPS. Getting there required the algorithm to work well with CockroachDB’s distributed architecture. We found good ways to map huge vector indexes to ranges so that they are automatically partitioned and distributed across the cluster. Searches avoid creating range hot-spots or high contention. Splits and merges “just work,” with no need for restrictions such as unsplittable ranges. With these “constraints” the algorithm and implementation we created conforms to the underlying database’s architectural rules, and CockroachDB “just does” the heavy-lifting of ensuring scalability.

K-means tree: Core data structure powering C-SPANN
Latency. We have chosen an algorithm that requires a small-ish, predictable number of serial network roundtrips to help limit latency. Latency overall isn’t as much of a concern for CockroachDB, given that it’s distributed and disk-based. Retrieving results in the low 10’s of milliseconds is likely good enough for most scenarios that run on CockroachDB, and we’ve accomplished that with this public preview.
Resource usage. One thing to consider when evaluating distributed SQL databases that implement “off the shelf” indexing algorithms is resource usage. If the indexing algorithm requires a multi-GB in-memory data structure it would need to be duplicated on every SQL node that processes queries because of the way that distributed SQL works. And, when it comes to CockroachDB Cloud, besides being wasteful, it would be impractical in our serverless offering (Cockroach Cloud Basic) to rebuild such a large data structure every time a transient SQL pod spun up.
Build performance. Indexes often need to be built (or rebuilt) in the background without impacting foreground traffic. This often means that builds can only use a fraction of available CPU and memory. Our approach (among other engineering feats) uses RaBitQ to keep the index size small, making it faster to build and search.
A vector database PLUS distributed SQL
See vector indexing in CockroachDB in action in this demo by technical evangelist, Rob Reid, going through an example of anomaly detection:
CockroachDB brings vector similarity searches into developer’s hands with the full power of SQL. This enables simple filtering, joins, and aggregations in combination with vector queries. Beyond simple nearest neighbor searches, developers can create sophisticated data retrieval searches. For example, you can look for all tickets of a certain type that are similar to a new inbound request by filtering on a ticket field before completing the similarity search.
Just as important, fast vector indexing enables data owners to take full advantage of CockroachDB’s key promises around resilience, scale, performance, geo-data placement, and low cost of ownership.






